crawlee-js
apify-platform
crawlee-python
💻hire-freelancers
🚀actor-promotion
💫feature-request
💻creators-and-apify
🗣general-chat
🎁giveaways
programming-memes
🌐apify-announcements
🕷crawlee-announcements
👥community
Crawlee Hybrid Crawler?
...(crawlerType === 'playwright' ? { launchContext: getLaunchContext() } : {}),
...(crawlerType === 'playwright' ? { launchContext: getLaunchContext() } : {}),
How to combine the scraping results for Crawlee Playwright actor?
Dataset.pushData....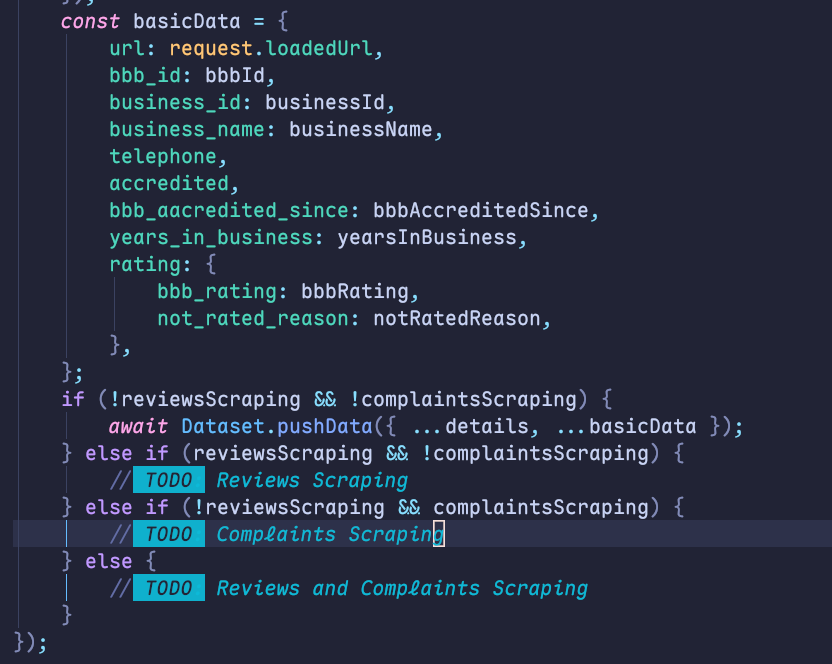
Crawl sitemap
const config = new Configuration({ persistStorage: false });
const config = new Configuration({ persistStorage: false });
FAcebook Ads library src video/images
Skip request in preNavigationHooks
postNavigationHooks timeout
Rotate country in proxy for each request
Crawleee js vs crawlee python
Managing duplicate queries using RequestQueue but it seems off.
re-enqueue request without throwing error
Configuring playwright + crawlee js to bypass certain sites
Target business owners #crawlee-js
Pure LLM approach
readability or unfluff to extract the main content, or filter DOM sections manually (like removing .footer, .nav, etc.). For trickier cases, you can even use the LLM to clean up pages before extraction.
Embedding-based filtering is also a nice option if you want to skip irrelevant pages before sending to the LLM, but it adds complexity. You're on the right track — it's just about fine-tuning the cleanup now....Anyone here automated LinkedIn profile analytics before?
X's terms of service
Invalidate request queue after some time
Apify Question:
crawlee/js playwrite help related to clicking
LinkedIn DM Sync to DB
Crawlee PuppeteerCrawler not starting with Chrome Profile