crawlee-js
apify-platform
crawlee-python
💻hire-freelancers
🚀actor-promotion
💫feature-request
💻creators-and-apify
🗣general-chat
🎁giveaways
programming-memes
🌐apify-announcements
🕷crawlee-announcements
👥community
bot detection (captcha) changed, Playwright+Crawlee+Firefox+rotating proxies does not help any more
chromium version error in path
Scrape JSON and HTML responses in different handlers
Playwright with Firefox: New Windows vs Tabs and Chromium-specific Features
headless: false mode to check how things look, and I've noticed it opens new windows for each URL instead of opening new tabs. Is there a way to configure this behavior? I'd prefer to have new tabs open instead of separate windows.
...crawlee.run only scrap the first URL
Router Class
WebRTC IP leak?
Crawlee Playwright is detected as bot
How can I wait with processing further logic untill all request from batch are proceeded
Puppeteer browser page stuck on redirections
Saving scraped data from dynamic URLs using Crawlee in an Express Server?

All requests from the queue have been processed, the crawler will shut down.
purgeOnStart=false so that I don't scrape duplicated news, however sometimes in some cases I got the message "All requests from the queue have been processed, the crawler will shut down." and the crawler don't run, any suggestion to fix this issue??Crawlee not working with cloudflare

How to define custom delimiter on the Dataset.exporToCSV method?
Express better then node with crawlee? Or is it really not any big difference?
How to use Playwright's bypassCsp option?
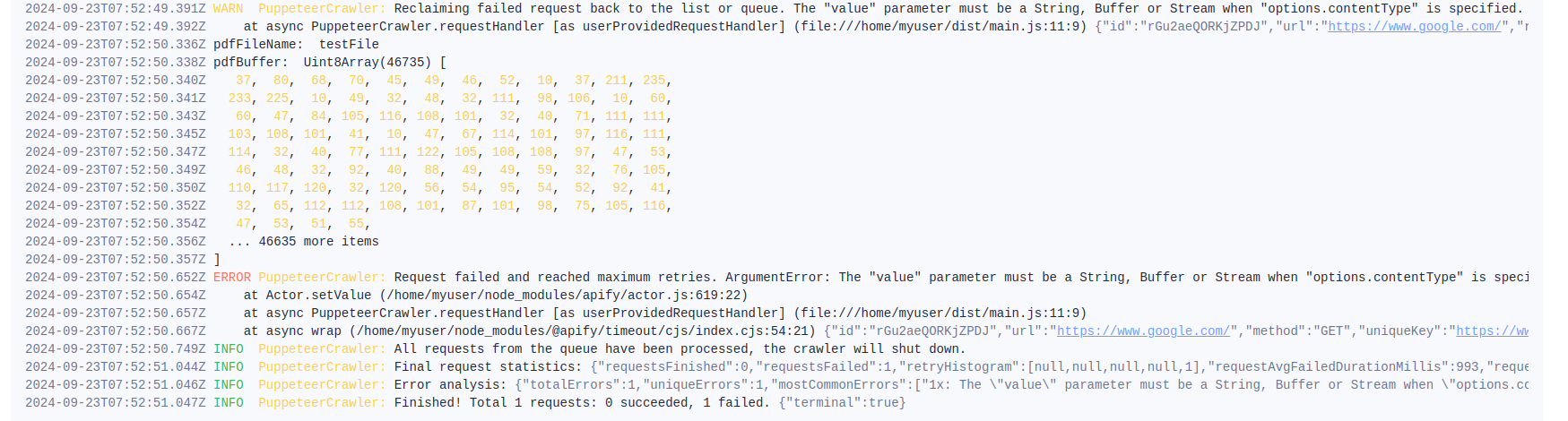
Save a webpage to a PDF file using Actor.setValue()
Any suggestions for improving the speed of the crawling run?
Prevent automatic reclaim of failed requests
How to make sure all external requests have been awaited and intercepted?
puppeteer because I found the addInterceptRequestHandler in the docs, but I could use Playwright if it's easier. Can someone here help me to understand what I'm doing wrong? Here is a gist with the code I'm using: https://gist.github.com/lcnogueira/d1822287d718731a7f4a36f05d1292fc (I can't post it here, otherwise my message becomes too long)...