crawlee-js
apify-platform
crawlee-python
💻hire-freelancers
🚀actor-promotion
💫feature-request
💻creators-and-apify
🗣general-chat
🎁giveaways
programming-memes
🌐apify-announcements
🕷crawlee-announcements
👥community
Fingerprints for session.
Packaging crawlee with pyinstaller
set user-agents for BeautifulSoupCrawler
Crawlee's Compatibility with Kivy
configure_logging=False when initializing the crawler.
```python...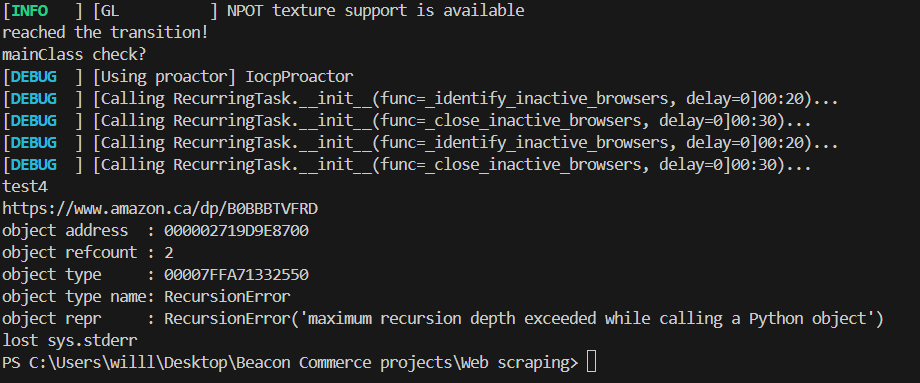
selenium + Residential Proxies
Memory access problem on MacOS
psutil.Process.memory_full_info(),...Unexpected behavior with Statistics logging
periodic_message_logger expects either some external logger, or if None, the default value is used.
You can achieve your goal by doing the following
```python...StorageClients w/ Multiple Crawlers
Issue with Instagram Reels Playcount Scraper – Restricted Page Errors
Get metadata in response of /run-sync via API
Using browser_new_context_options with PlaywrightBrowserPlugin

enqueue_links does not find any links
Crawler always stops after exactly 300 seconds
Searching for Developer of Apollo scraper 50k leads-code_crafter
Scrapping tweets are all mock tweets
How to send an URL with a label to main file?
Memory is critically overloaded
CRAWLEE_MEMORY_MBYTES is set to 61440
My docker config
```...
Routers not working as expected