crawlee-js
apify-platform
crawlee-python
💻hire-freelancers
🚀actor-promotion
💫feature-request
💻creators-and-apify
🗣general-chat
🎁giveaways
programming-memes
🌐apify-announcements
🕷crawlee-announcements
👥community
Question for any team members: if you
I need help, I have the Scale plan and
Any members of the team: I'd like to
you need to explicitly pass the
requestQueueId when starting the actor.in the python sdk is there a way to get
Hi! I'm building something using the
excludeUrlGlobs the right input setting for this?
Is there a limit on exclusions? The plan is to regularily crawl news sites but i would like to only process something if there is new (not previously visited urls) data found....Hello guys,

Support regarding website content crawlrr
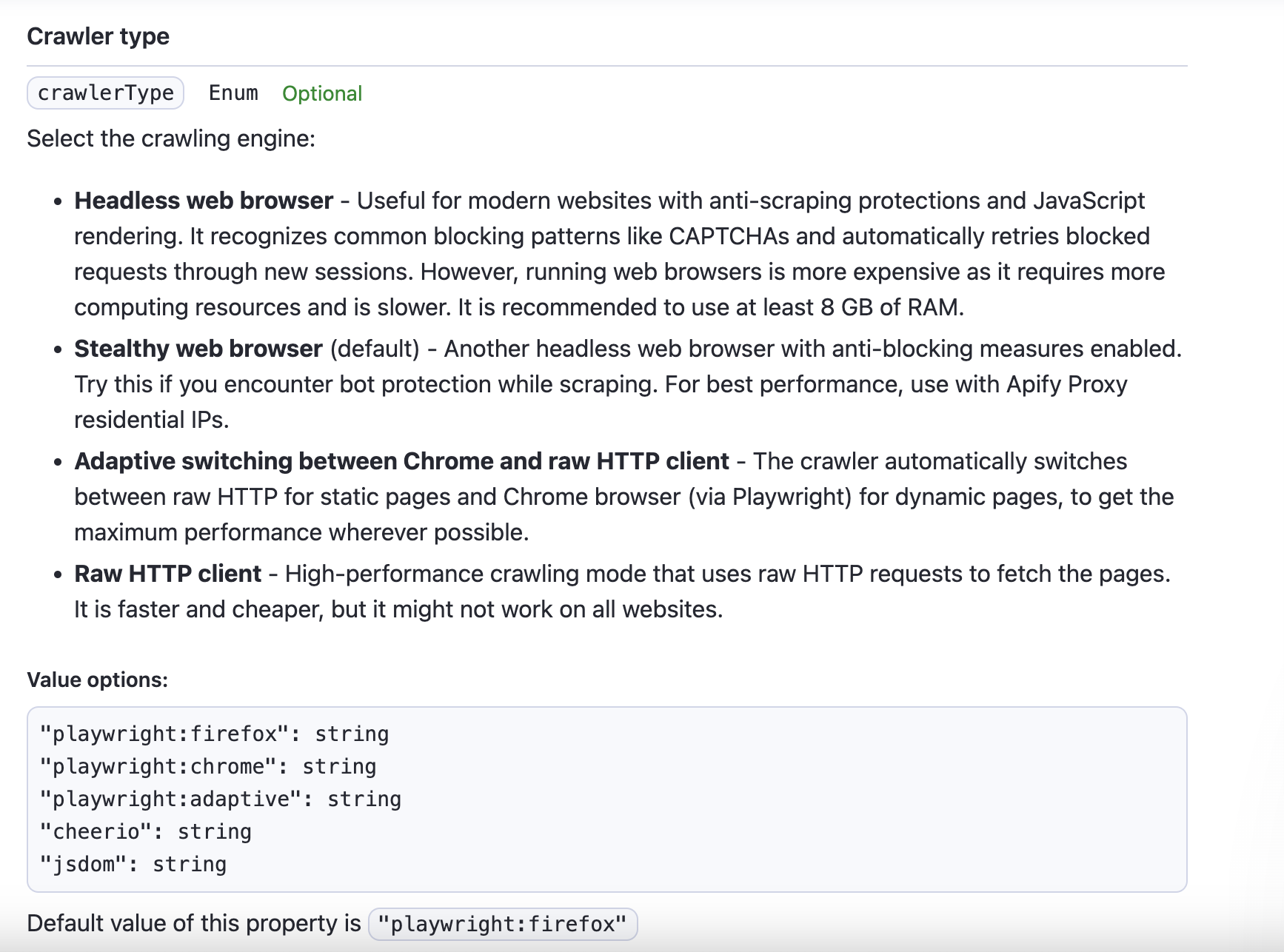
Hi there! Does anybody know how to
I have made a scrapper. and I have
Excuse me, i have a problem.If i want to
Hi I am using Smart Article Extractor
Hi, I am currently trying to split up
Hello everyone,
Hi, I am building a webscraper and I
Hey does anyone know if i can
hi, thank you for the tool
ERROR Actor failed with an exception
Traceback (most recent call last):
File "/usr/src/app/src/main.py", line 150, in main
actor_input = await Actor.get_input()
^^^^^^^^^^^^^^^^^^^^^^^ ...