technological-jade
{"time":"2024-05-20T03:04:41.809Z","level":"WARNING","msg":"PuppeteerCrawler:AutoscaledPool:Snapshot
This error is happening consistently, even while only running 1 browser. When I load up the server and look at
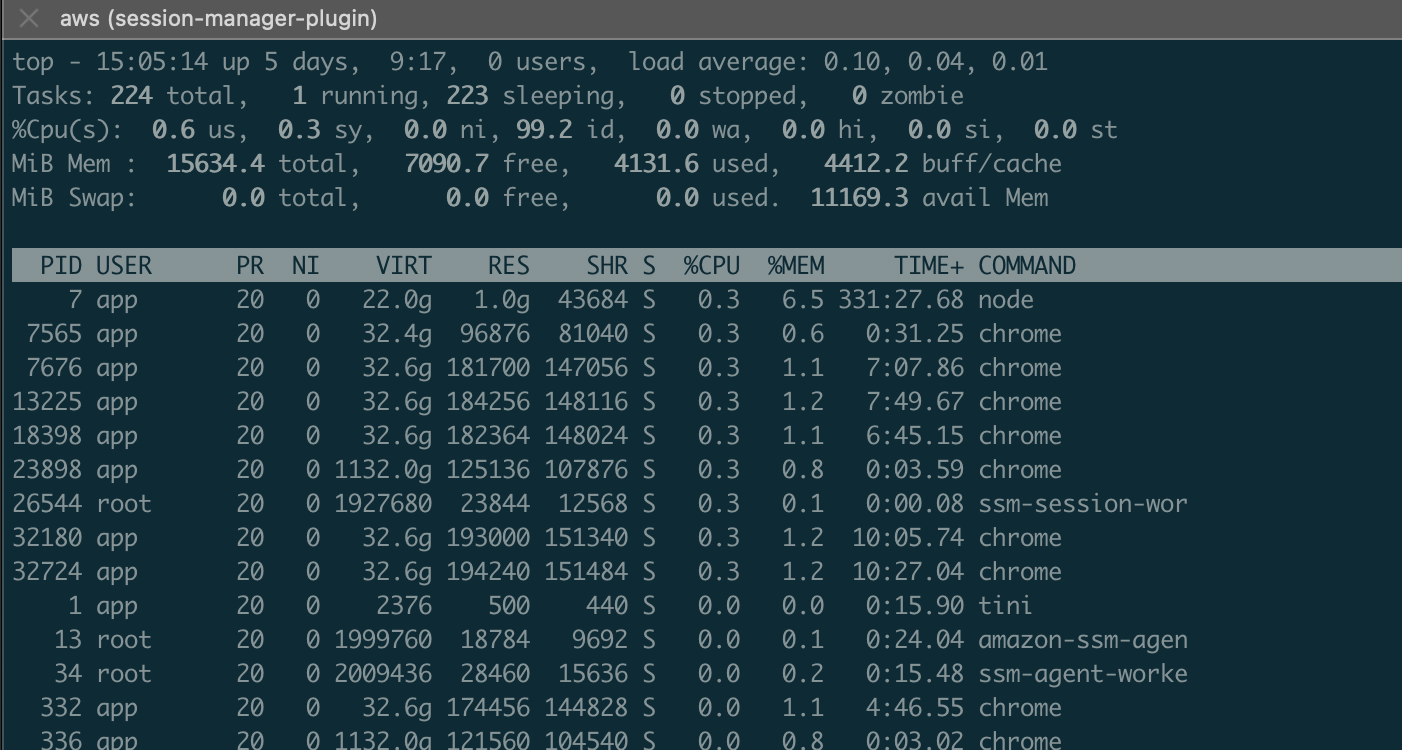
top attached.:
Error:
toptop attached.:
Error:

This is the official developer community of Apify and Crawlee.
14,091Members
Resources
Recent Announcements
Similar Threads
Was this page helpful?
